


The Companies Behind China’s Robotics Powerhouse
Why China’s humanoid industry is accelerating faster than expected.
.webp)
October 19, 2025
Category:
Physical AI
Read time:
Share This:
Co-Author: Hub
Imagine asking a humanoid robot in your home to “grab the red mug from the kitchen counter and bring it to me”. A task like this, trivial for humans, requires a robot to see the environment, hear and understand your words, and then act on the physical world.
This fusion of vision, language understanding, and action is at the heart of the latest AI models for robotics, also known as Visual-Language-Action (VLA) models.
These VLA models empower robots to perceive their surroundings, interpret natural language instructions, and execute complex tasks with precision. The promise?
A future where home robots assist with everyday chores through simple voice commands, from tidying up to preparing meals. To make this vision a reality, VLA models require something fundamental: vast amounts of real-world data.
In this article, we explore how researchers and companies are collecting and leveraging real-life data to train VLA models, the challenges they face, and the remarkable progress being made to bring intelligent, capable robots into our homes.
We also dive into the rise of foundational world models, AI systems that simulate and predict real-world dynamics, paving the way for robots that can learn, adapt, and interact more naturally in diverse environments.
Our homes are unstructured, dynamic environments, unlike the tidy, repetitive setting of a factory floor. No two living rooms or kitchens are exactly the same, and people use objects in endlessly varied ways. On top of this, humans in factories are way more predictable than kids in homes. This an additional complexity that makes home robotics so much more challenging than industrial robotics. Yet, this is the challenge that 1X Technologies has decided to tackle.
Traditional robots such as autonomous vacuum cleaners have struggled in homes because they were hard-coded for specific tasks and couldn’t adapt well to new situations.
VLA models offer a new approach: instead of pre-programming every action, robots are trained on large datasets of demonstrations and experiences so that they can generalize and figure out what to do when they face new situations.
A VLA model essentially integrates three main capabilities:
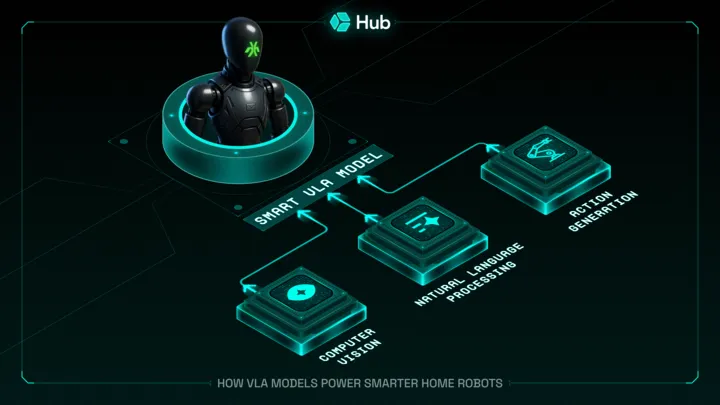
By combining these, a VLA-equipped robot can link what it sees to what it’s being told and decide how to act. For example, a well-trained VLA model allows a robot to comprehend a command like, “Wipe the coffee spill near the blue mug on the table,” then visually identify the spill and the blue mug, plan a sequence of motions to navigate and wipe the spill, and execute that plan. This represents a huge leap in flexibility and intelligence for home robots compared to earlier generations.
If vision-language-action models are the “minds” of a humanoid robot, running on the “brains”, i.e. the powerful processors, data is the oxygen that makes those brains function.
Unlike language models or image-recognition systems, which can be trained on vast datasets scraped from the web, home robots require embodied experiences, i.e. data pairing visual inputs, actions, and outcomes in real-world settings. For example, teaching a robot to “load a dishwasher” involves more than just conceptual knowledge; it demands recordings of the entire end-to-end process: physical motions, object interactions, and environmental variations involved in the task.
However, collecting large-scale, diverse robotic data is expensive and complex. Every home is unique, with varied layouts, objects, and user behaviours. To achieve general competency, a robot must encounter countless scenarios, different objects, environments, tasks, and edge cases.
Unlike sourcing millions of internet images for vision models, there’s no simple way to crowdsource real-world robot experiences. Data must be gathered through labor-intensive methods like autonomous robot operations (programming robots to collect data independently, which is complex and risky) or human teleoperation (humans manually guiding robots to perform tasks), both of which are time-consuming and costly.
Consider an example from Toyota Research Institute (TRI): researchers trained a robot’s vision model using images of cluttered tables to teach it object recognition and grasping. When the robot encountered an empty table, it struggled, as this scenario differed from its training data.
The solution? Collecting additional images of empty tables across various settings: a slow, labor-intensive process. This underscores a key challenge: human environments are infinitely varied, requiring extensive real-world data to cover diverse scenarios and edge cases effectively.
This article focuses on real-world data, but it’s worth highlighting that most robotics teams augment their datasets with simulations. Simulators can generate countless variations of environments, such as kitchens with diverse layouts, lighting, or object placements, without the expense and limitations of physical trials.
Initially, teams used procedural generation, akin to 3D video game techniques, to create synthetic videos with a physics engine able to simulate the physical world. These help train vision systems on rare or hazardous scenarios that are difficult to replicate in reality.
A more advanced approach involves World Foundation Models (WFMs), large-scale generative models that simulate real or virtual environments, including their physics, dynamics, and visuals. NVIDIA introduced WFMs in the context of “Physical AI” to describe neural networks that act as general-purpose world models.
A WFM processes multimodal inputs (text, images, or videos) to produce realistic continuations or simulations, typically as video frames. Essentially, WFMs serve as digital twins of physical environments, enabling AI agents to interact safely or query scenarios. NVIDIA’s glossary notes that WFMs “simulate real-world environments as videos and predict accurate outcomes based on text, image, or video inputs."
WFMs are called “foundation models” because they are trained on vast, diverse datasets—such as countless videos of physics-rich activities, to capture general world dynamics. These models can then be fine-tuned for specific tasks or domains. NVIDIA’s Cosmos platform, for example, offers a suite of pre-trained WFMs that can be adapted for various applications, such as different robots or vehicles, through targeted fine-tuning.
In practice, the most powerful training regimes use a blend of real and synthetic data , real data grounds the model in actual physics and sensor quirks, while synthetic data fills in the gaps and broadens diversity.
Researchers and companies have become creative in how they capture the real-world data needed to train VLA models for home robotics. A few key methods have emerged:
Fleet Learning: Using multiple robots to gather data in parallel. For example, Tesla’s fleet of vehicles captures driving scenarios, feeding vast amounts of footage into its Dojo system to train self-driving models. Similarly, Google deployed 13 wheeled robots with arms in a mock kitchen over 17 months, collecting 130,000+ task episodes across 700+ distinct tasks (e.g., picking up toys, opening drawers, fetching items). Each robot, remotely operated by humans, recorded actions paired with text instructions, creating a rich dataset of (situation, instruction, action) tuples. This effort produced the Robotics Transformer 1 (RT-1) model, achieving a 97%+ success rate on trained tasks and demonstrating generalization—e.g., picking up new objects like a book on a table, even if untrained on that specific scenario.
Teleoperation: Researchers at TRI’s Cambridge, MA lab use virtual reality or specialized controllers to teleoperate robotic arms, guiding them through tasks like sweeping spilled beans with a dustpan. These human-demonstrated motions are recorded, allowing the robot to replicate them autonomously. For example, after a journalist taught a robot to sweep beans and practiced further in simulation, the robot mastered the task independently. Teleoperation enables humans to directly transfer their dexterity and decision-making into the robot’s dataset, enhancing its learning. We believe that tele-operation will play a critical role in the first years of humanoid robots deployment. This will be the way for humanoid to be more useful as human experts will be able to handle tricky situations and it will also be a way for humanoid to capture new data and learn new skills.
Learning from Human Videos: A promising new approach involves robots learning from human behavior videos, like YouTube’s countless how-to clips. Large Language Models (LLMs), such as those powering ChatGPT, hold vast general knowledge about tasks like “cleaning spills” or “peeling vegetables,” but lack physical context, as TRI’s Russ Tedrake notes: “Without real-world interaction, YouTube videos alone aren’t enough.” The goal is to combine LLMs’ conceptual understanding with physical grounding from real or simulated practice. For instance, a robot could watch a dishwasher-loading video to grasp the concept, then refine its actions in a real or simulated kitchen. Google DeepMind’s RT-2 model, for example, was trained on internet data and fine-tuned with robotics data, enabling it to interpret high-level commands and reason (e.g., selecting an energy drink for a tired person). This shows web-scale data provides semantic understanding, but real-world data remains essential for accurate actions.
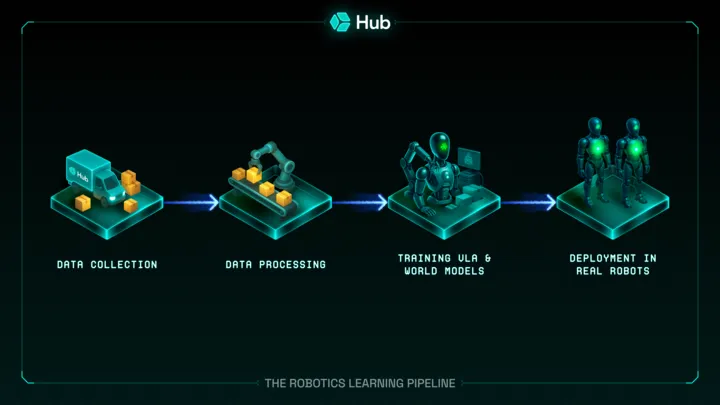
Robots are making significant progress in performing tasks in home-like environments. 1X Technologies, a leader in developing humanoid robots for domestic use, has showcased their NEO series in various demonstrations, highlighting their potential as versatile home helpers.
In a notable demonstration in November 2024, the NEO Beta robot collaborated with YouTube chef Nick DiGiovanni to cook a steak. Although teleoperated, it successfully operated the gas stove, added olive oil, and flipped the steak with a spatula, showcasing its potential for complex household tasks. Beyond cooking, 1X Technologies has outlined additional capabilities for NEO robots. According to an NVIDIA blog post from June 4, 2025, NEO can perform household tasks such as vacuuming, folding laundry, tidying, and retrieving items. These capabilities are supported by a combination of reinforcement learning, expert demonstrations, and real-world data, as explained by 1X CEO Bernt Øyvind Børnich. The introduction of NEO Gamma, unveiled on February 21, 2025, further enhances these abilities, featuring improvements in hardware and AI, including a visual manipulation model capable of picking up a large variety of objects in different scenarios, as detailed on their website.
Training vision-language-action (VLA) models for home robotics faces significant hurdles:
Scale vs. Practicality: Robust performance requires vast, diverse data. Google’s 130,000 demonstrations and 1X Technologies’ extensive robot trials cover only a fraction of home scenarios. Scaling data collection demands deploying robots in diverse homes or building comprehensive simulation libraries. Researchers aim to leverage web-pretrained AI for better generalization, minimizing real-world data needs, an active area of exploration.
Safety and Error Handling: Trial-and-error learning in homes risks mishaps, like damaging valuables. Most data collection occurs in controlled labs or under supervision, creating a catch-22: robots need real-world experience to improve, but cannot roam freely until reliable. Solutions include safe simulations and robust safety protocols, with the goal of enabling autonomous data collection as models mature.
Privacy and Acceptance: Robots recording home environments raise privacy concerns, as seen with vacuum mapping controversies. Transparent, secure data practices are critical for trust, ensuring no sensitive data reaches cloud servers without consent. Crowdsourcing anonymized data from volunteer users, akin to autonomous vehicle programs, could accelerate progress if privacy is prioritized.
Human Environment Complexity: Homes are physically and socially complex, requiring robots to grasp subtle cues (e.g., what to tidy or how to handle pets). Current VLA models focus on physical tasks, but future training must incorporate contextual nuances, like user preferences for “correct” or “polite” actions, integrating end-user feedback into the learning loop.
Decentralized data gathering, powered by Web3 technologies like Decentralized Physical Infrastructure Networks (DePIN), could revolutionize how robotics datasets are created and shared. DePIN enables distributed networks of devices, such as IoT sensors, or smartphones manipulated by users, to collect and share real-world data securely and anonymously, incentivizing participation through token-based rewards.
This approach enables open datasets that are diverse, scalable, and accessible, reducing reliance on centralized labs. For instance, robots in homes worldwide could contribute task data (e.g., folding laundry or cooking) to a blockchain-secured dataset, ensuring privacy while enriching AI training. By leveraging DePIN, humanoid robotics companies could tap into global, community-driven data pools, accelerating the development of versatile, general-purpose home robots with enhanced real-world adaptability.
The field of home robotics is on the cusp of transformative breakthroughs. Advances in AI, driven by deep learning, combined with innovative real-world data collection, are turning the sci-fi vision of helpful home robots into reality. Much like the early days of personal computers or smartphones, today’s prototypes, though imperfect, show the pieces falling into place. In the near future, robots could become as ubiquitous in homes as refrigerators, seamlessly handling chores. Achieving this requires mastering real-world data and training to instill machines with human-like competence and common sense.
Sources: The information and examples in this article are based on current research and industry developments in robotics and AI. Key references include Google/DeepMind’s work on Robotics Transformer models, Toyota Research Institute’s approaches to robot learning via teleoperation and simulation, and news from companies like Dyson and Amazon on their home robotics ventures, among others. All quotes and technical details are sourced from these reports and publications to ensure accuracy.
XMAQUINA is a decentralized ecosystem giving members direct access to the rise of humanoid robotics and Physical AI, technologies set to reshape the global economy.
Join thousands of futurists contributing to the XMAQUINA DAO and follow us on X for the latest updates. Explore the DAO’s portfolio here: dao.xmaquina.io
Owner:
.png)
.png)
